Evaluate the presence of sample level batch effects by PILOT (Trajectory)
import PILOT as pl
import scanpy as sc
from matplotlib.cm import get_cmap
import seaborn as sns
import pandas as pd
Reading the original Anndata:
First, we consider the original kidney single cell data. You can download the Anndata (h5ad) file from here, and place it in the Datasets folder.
adata = sc.read_h5ad('/Datasets/kidney_ori.h5ad')
Loading the required information and computing the Wasserstein distance:
Use the following parameters to configure PILOT for your analysis (Setting Parameters):
adata: Pass your loaded Anndata object to PILOT.
emb_matrix: Provide the name of the variable in the obsm level that holds the dimension reduction (PCA representation).
clusters_col: Specify the name of the column in the observation level of your Anndata that corresponds to cell types or clusters.
sample_col: Indicate the column name in the observation level of your Anndata that contains information about samples or patients.
status: Provide the column name that represents the status or disease (e.g., “control” or “case”).
pl.tl.wasserstein_distance(
adata,
emb_matrix = 'X_pca',
clusters_col = 'cell_type',
sample_col = 'donor_id',
status = 'disease'
)
Trajectory estimation:
pl.pl.trajectory(adata, colors = ['red','orange','Blue'])
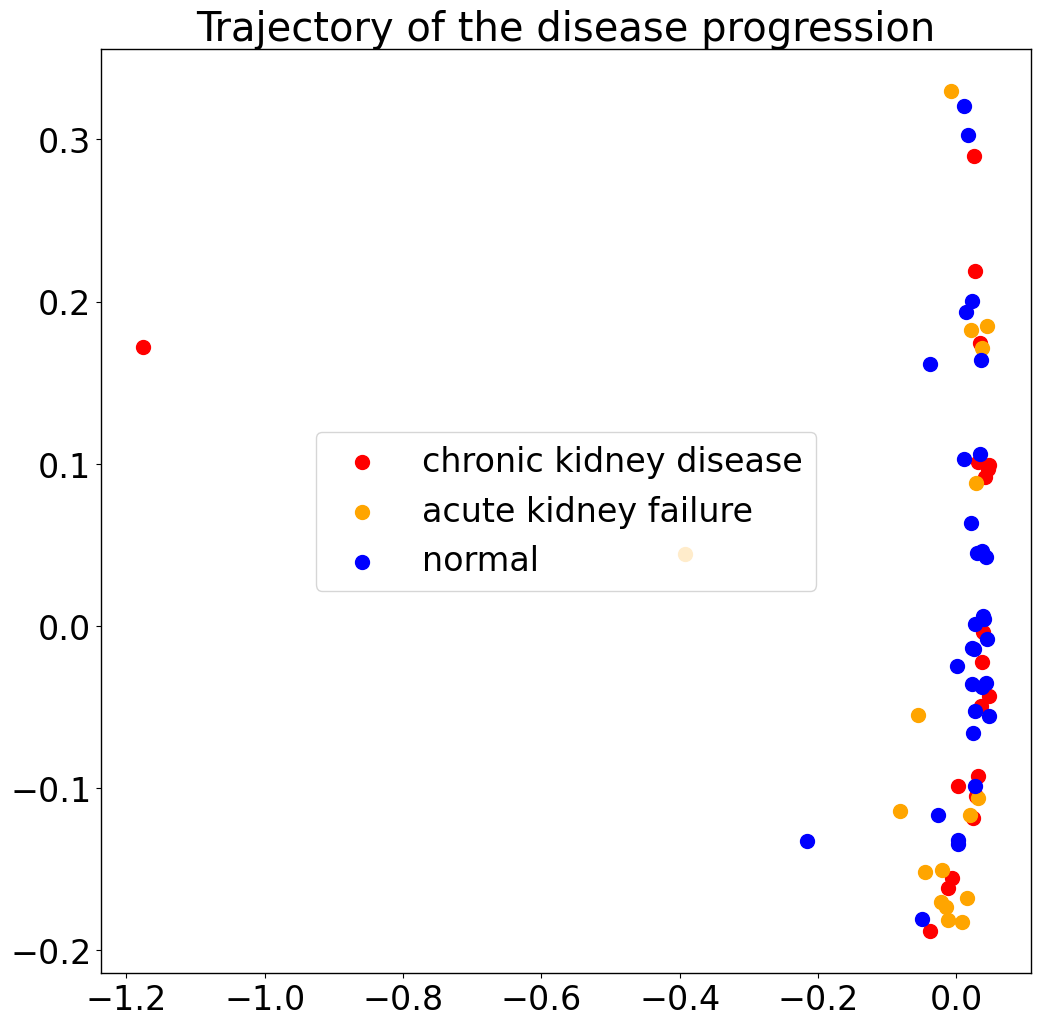
Then, estimate the trajectory by fitting a principle graph and calculate the order of samples by ‘cell_importance’ functions. See the main tutorial, for details.
pl.pl.fit_pricipla_graph(adata, source_node = 8)
pl.tl.cell_importance(adata,heatmap_w = 20,height = 15,xlim = 30)
Evaluation of the association of estimated disease progression with experimental factor:
A very important question is if PILOT analysis is affected by experimental artefacts (location of tissues, batch processing). To evaluate this, we use ANOVA statistics and Spearman correlation to check any association between any variables describing the disease cohort and the predicted variables.
To run these functions, provide the sample_col as the Sample/Patientcolumns and your variables of interest. Of note, these functions only show the significant variables (p-value < 0.05).
numeric = ['degen.score','aStr.score','aEpi.score','matrisome.score','collagen.score','glycoprotein.score','proteoglycan.score']
categorical = ['BMI','hypertension','development_stage','sex','eGFR','diabetes_history','disease','tissue']
Categorical variables
pl.tl.correlation_categorical_with_trajectory(adata, sample_col = 'donor_id', features = categorical)
| Feature | ANOVA_FStatistic | ANOVA_PValue | |
|---|---|---|---|
| 7 | tissue | 9.772883 | 0.000022 |
| 5 | diabetes_history | 3.429356 | 0.038475 |
Numerical variables :
Similarly, you can do the same analysis for numerical variables.
pl.tl.correlation_numeric_with_trajectory(adata, sample_col = 'donor_id', features = numeric)
| Feature | Spearman_Correlation | Spearman_PValue | |
|---|---|---|---|
| 0 | degen.score | 0.262272 | 0.032027 |
We observe that there is a clear association between the trajectory and the origin of the biopsies. This is not surprising as PILOT uses cellular composition information, as samples at distinct regions do have distinct cells. Regarding continuous variable, we find an association with the degen.score, which is a gene signature score estimated from the comparisons of controls and disease samples (see data manuscript for more details https://doi.org/10.1038/s41586-023-05769-3).
To double check these results, one can of course plot the trajectory by showing the location as labels.
Tissue
palette = sns.color_palette("husl", len(adata.obs['tissue'].unique()))
colors = [palette[i] for i in range(len(adata.obs['tissue'].unique()))]
pl.tl.wasserstein_distance(
adata,
emb_matrix = 'X_pca',
clusters_col = 'cell_type',
sample_col = 'donor_id',
status = 'tissue'
)
pl.pl.trajectory(adata, colors = colors)
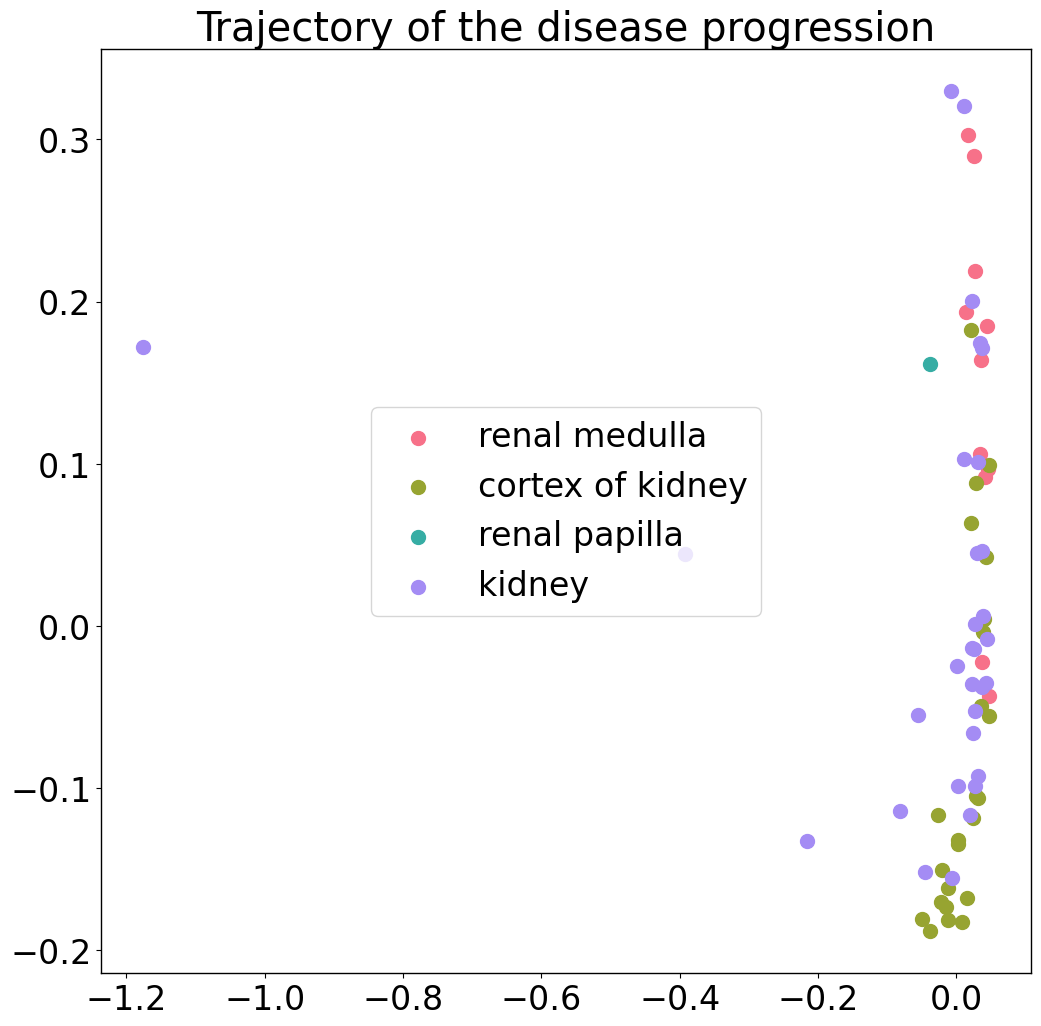
Filtering of samples
Therefore, we only focus on biopsies from sample locationn ‘kidney’, which were used in our benchmarking. You can download the Anndata (h5ad) file from here, and place it in the Datasets folder.
adata_filtered=sc.read_h5ad('/Datasets/Kidney.h5ad')
pl.tl.wasserstein_distance(
adata_filtered,
emb_matrix ='X_pca',
clusters_col='cell_type',
sample_col='donor_id',
status='disease'
)
pl.pl.trajectory(adata_filtered, colors = ['red','orange','Blue'])
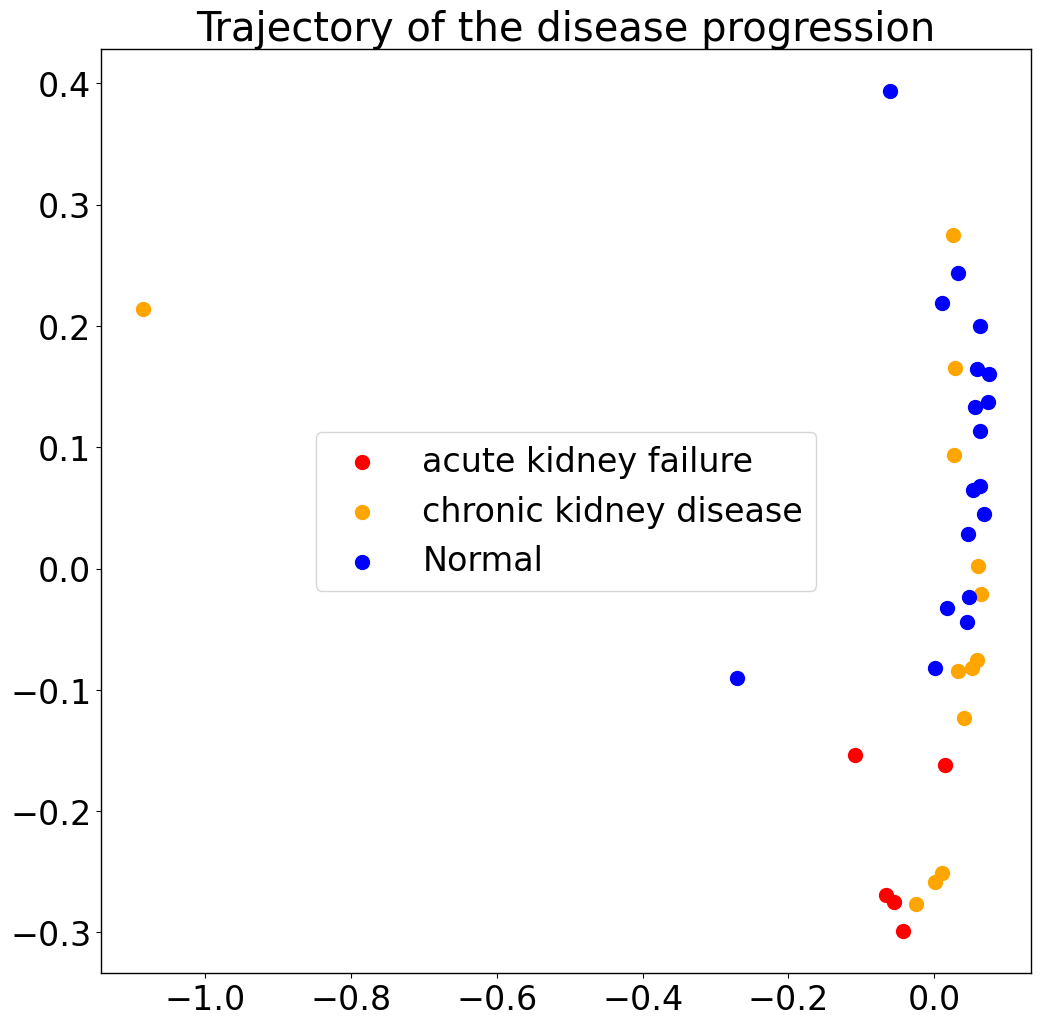
Categorical variables
We next recheck the association of variables with the estimated trajectory.
pl.tl.correlation_categorical_with_trajectory(adata_filtered, sample_col='donor_id', features=['BMI','hypertension','development_stage','sex','eGFR','diabetes_history','disease'])
| Feature | ANOVA_FStatistic | ANOVA_PValue | |
|---|---|---|---|
| 6 | disease | 9.457675 | 0.000566 |
| 5 | diabetes_history | 12.517843 | 0.001189 |
| 0 | BMI | 3.969681 | 0.016358 |
We observed data the true label (disease) has highest association followed by BMI or Diabetes History. While the latter are two clinical factors with a impact on kidney disease, as closer investigation of the variables indicates these association as spurious, as only controls have BMI values and most disease are diabetic.
Diabetes_history
contingency_table = pd.crosstab(adata_filtered.obs['disease'], adata_filtered.obs['diabetes_history'],values=adata_filtered.obs['donor_id'], aggfunc=pd.Series.nunique, margins=True, margins_name='Total Unique Patients')
contingency_table
| diabetes_history | No | Yes | Total Unique Patients |
|---|---|---|---|
| disease | |||
| Normal | 18.0 | NaN | 18 |
| acute kidney failure | NaN | 5.0 | 5 |
| chronic kidney disease | NaN | 13.0 | 13 |
| Total Unique Patients | 18.0 | 18.0 | 36 |
BMI
contingency_table = pd.crosstab(adata_filtered.obs['disease'], adata_filtered.obs['BMI'],values=adata_filtered.obs['donor_id'], aggfunc=pd.Series.nunique, margins=True, margins_name='Total Unique Patients')
contingency_table
| BMI | 18.5—24.9 | 25.0—29.9 | 30.0 and Above | unknown | Total Unique Patients |
|---|---|---|---|---|---|
| disease | |||||
| Normal | 2.0 | 11.0 | 4.0 | 1.0 | 18 |
| acute kidney failure | NaN | NaN | NaN | 5.0 | 5 |
| chronic kidney disease | NaN | NaN | NaN | 13.0 | 13 |
| Total Unique Patients | 2.0 | 11.0 | 4.0 | 19.0 | 36 |